




Alibaba Rilis Qwen 3.5 Omni, Model AI yang Bisa Kloning Suara Pengguna
- Tim Qwen dari perusahaan teknologi asal China, Alibaba, merilis model kecerdasan buatan (artificial intelligence/AI) terbarunya, yakni Qwen 3.5 Omni, pada Minggu (29/3/2026).
Model ini menjadi salah satu pembaruan paling ambisius dari Alibaba karena menghadirkan versi baru dari AI "omnimodal" yang dapat memproses berbagai jenis input sekaligus. Mulai dari teks, gambar, audio, hingga video, bisa diproses secara bersamaan.
Salah satu fitur yang paling menonjol dari Qwen 3.5 Omni adalah kemampuannya dalam mengkloning suara (voice cloning).
Dengan fitur ini, pengguna dapat mengunggah sampel suara, lalu AI akan merespons menggunakan suara tersebut.
Baca juga: Alibaba Rilis Qwen 3.5, Model Agen AI Lebih Murah dan Ungguli GPT hingga Gemini
Fitur kloning suara ini menempatkan Qwen 3.5 Omni sebagai pesaing langsung layanan AI suara pesaing, salah satunya yaitu ElevenLabs. Namun, untuk saat ini, kemampuan kloning tersebut baru tersedia melalui akses API.
Fitur suara lebih cerdas
Masih soal suara, Qwen 3.5 Omni juga dibekali kemampuan cerdas lain untuk berinteraksi secara langsung (real-time) dalam percakapan suara.
Model ini dibekali fitur "semantic interruption", yang memungkinkan AI memahami kapan pengguna benar-benar ingin "menyela" percakapan.
Sederhananya, AI ini tidak akan berhenti berbicara hanya karena gangguan kecil, seperti suara latar atau respons singkat seperti "iya" atau "eh" dan "hmm". Dengan begitu, alur percakapan jadi terasa lebih natural.
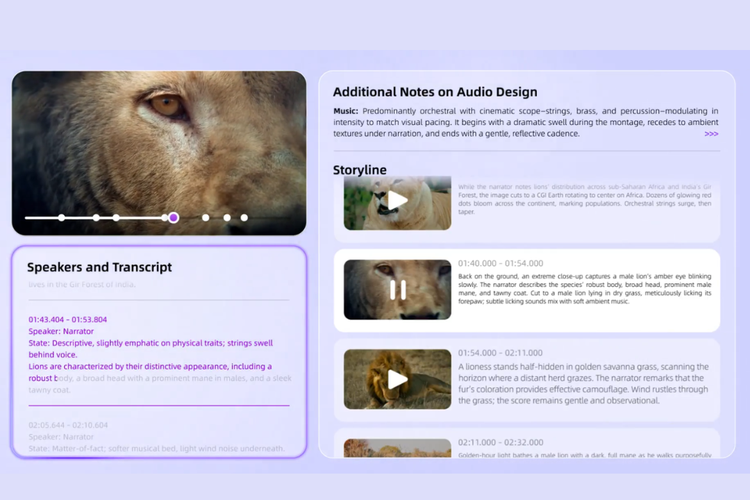 Qwen 3.5 Omni mampu menganalisis video secara langsung, mulai dari mengenali siapa yang berbicara, topik yang dibahas, hingga memberikan komentar berdasarkan konteks.Fitur baru lainnya, Alibaba juga memperkenalkan teknologi baru bernama ARIA (Adaptive Rate Interleave Alignment), yang berfungsi menyelaraskan teks dan suara secara dinamis.
Qwen 3.5 Omni mampu menganalisis video secara langsung, mulai dari mengenali siapa yang berbicara, topik yang dibahas, hingga memberikan komentar berdasarkan konteks.Fitur baru lainnya, Alibaba juga memperkenalkan teknologi baru bernama ARIA (Adaptive Rate Interleave Alignment), yang berfungsi menyelaraskan teks dan suara secara dinamis.
Teknologi ini diklaim mampu membantu mengurangi kesalahan pengucapan, terutama pada angka atau kata-kata yang tidak umum.
ARIA juga memungkinkan sinkronisasi antara teks dan suara secara dinamis sehingga hasil keluaran lebih natural dan akurat.
Baca juga: Alibaba Rilis Qwen-Image-2512, AI Gambar Open Source Penantang Google
Bisa pahami video dan audio sekaligus
Berbeda dari sebagian besar model AI lain yang masih mengandalkan teks sebagai perantara, Qwen 3.5 Omni mampu memroses teks, gambar, audio, dan video secara langsung (native) dalam satu sistem.
Pendekatan ini dinilai membuat pemrosesan menjadi lebih cepat dan hasilnya lebih konsisten dibandingkan metode multimodal yang menggabungkan beberapa model terpisah, seperti ChatGPT.
Qwen 3.5 Omni sendiri dilatih menggunakan lebih dari 100 juta jam data audio-visual. Adapun skala pelatihan ini membuat kemampuannya berada di kelas berbeda dengan model AI milik pesaing.
 Model AI Qwen 3.5 Omni kini tersedia melalui layanan cloud Alibaba dan dapat diakses untuk berbagai kebutuhan berbasis AI.
Model AI Qwen 3.5 Omni kini tersedia melalui layanan cloud Alibaba dan dapat diakses untuk berbagai kebutuhan berbasis AI.
Untuk melihat kemampuannya, Qwen 3.5 Omni dibandingkan dengan ChatGPT 5.4 (mode thinking), keduanya diuji menggunakan video YouTube Short yang sama.
Hasilnya, Qwen 3.5 Omni mampu memroses video tersebut secara langsung dan memberikan analisis lengkap dalam waktu sekitar satu menit, mencakup siapa yang berbicara, topik pembahasa, serta komentar berdasarkan konteks.
Sebaliknya, ChatGPT 5.4 harus melalui beberapa tahapan terpisah, seperti mengekstrak frame video, memrosesnya dengan model visi, mentranskripsi audio menggunakan Whisper, serta membaca subtitle dengan OCR.
Seluruh tahapan tersebut membutuhkan waktu sekitar sembilan menit, lebih lama dari Qwen 3.5 Omni bahkan dalam kondisi ideal.
Baca juga: Alibaba Rilis Qwen-Image, AI Pembuat Gambar yang Mampu Menampilkan Teks dengan Jelas
Dukung hingga 113 bahasa
Qwen 3.5 Omni mendukung interaksi dalam banyak bahasa. Model ini mampu memahami hingga 113 bahasa dan dialek untuk pengenalan suara, meningkat dari generasi sebelumnya yang hanya mendukung 19 bahasa.
Dalam pengujian lain, AI juga tercatat mampu menangani percakapan dalam berbagai bahasa, seperti Spanyol, Portugis, dan Inggris. Model AI ini bahkan dapat berpindah bahasa di tengah percakapan tanpa kehilangan konteks.
Dalam benchmark stabilitas suara multibahasa, Qwen3.5 Omni Plus mengungguli ElevenLabs, GPT-Audio, dan Minimax di 20 bahasa.
Performa meningkat, bisa bikin kode dari rekaman video
Sebagai informasi, Qwen 3.5 Omni tersedia dalam tiga varian, yaitu Plus, Flash, dan Light, dengan context window hingga 256.000 token.
Pada pengujian benchmark, varian Qwen 3.5 Omni Plus dilaporkan mampu mengungguli model AI buatan Google, Gemini 3.1 Pro dalam sejumlah aspek, meliputi pemahaman audio, penalaran, terjemahan, serta setara dalam pemahaman audio-visual.
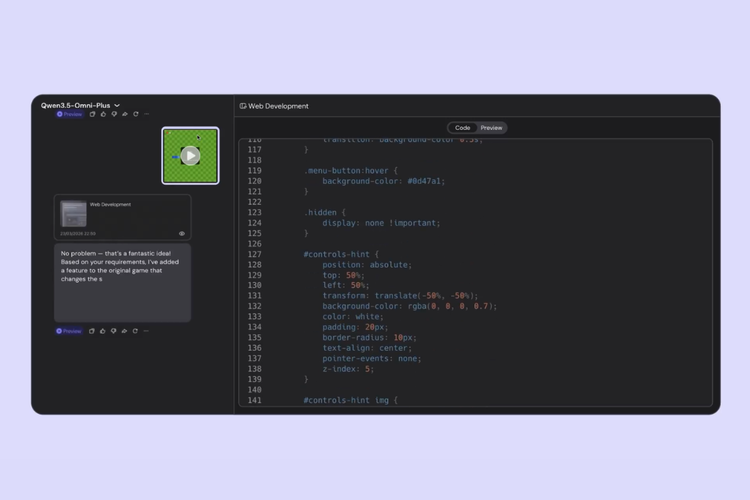 Qwen 3.5 Omni mampu menghasilkan kode secara otomatis dari input visual dan audio melalui fitur Audio-Visual Vibe Coding.Alibaba turut menyematkan fitur yang disebut dengan Audio-Visual Vibe Coding. Lewat fitur ini, AI dapat menonton video atau rekaman layar dari proses coding, lalu menghasilkan kode yang berfungsi tanpa perlu instruksi teks.
Qwen 3.5 Omni mampu menghasilkan kode secara otomatis dari input visual dan audio melalui fitur Audio-Visual Vibe Coding.Alibaba turut menyematkan fitur yang disebut dengan Audio-Visual Vibe Coding. Lewat fitur ini, AI dapat menonton video atau rekaman layar dari proses coding, lalu menghasilkan kode yang berfungsi tanpa perlu instruksi teks.
Kemampuan ini disebut menjadi gambaran terkait bagaimana asisten AI di masa depan dapat bekerja langsung di dalam alur kerja pengguna, bukan hanya sebagai alat pendamping.
Qwen 3.5 Omni sendiri saat ini sudah tersedia melalui API Alibaba Cloud. Model ini juga dapat diuji langsung melalui layanan Qwen Chat maupun demo online di platform Hugging Face, sebagaimana dihimpun KompasTekno dari decrypt.
Tag: #alibaba #rilis #qwen #omni #model #yang #bisa #kloning #suara #pengguna
KOMENTAR
BERITA TERKAIT

BERITA LAIN DALAM KATEGORI INI





